
Hin und wieder ist man mit doppelten Einträgen in einer Datenbank und dem Problem der Beseitigung konfrontiert. Nachfolgend zeige ich einen Weg, wie sich per SQL Duplikate effektiv finden und entfernen lassen.
Meine Test-Tabelle ist eine einfache Adresstabelle mit etwas über 400.000 Datensätzen und etlichen Duplikaten.
Der übliche Tipp zum Auffinden von Duplikaten mit Hilfe von GROUP BY und HAVING COUNT(*)>1 ist aber in meinen Augen sehr unpraktisch, wie die folgende Abbildung verdeutlicht.
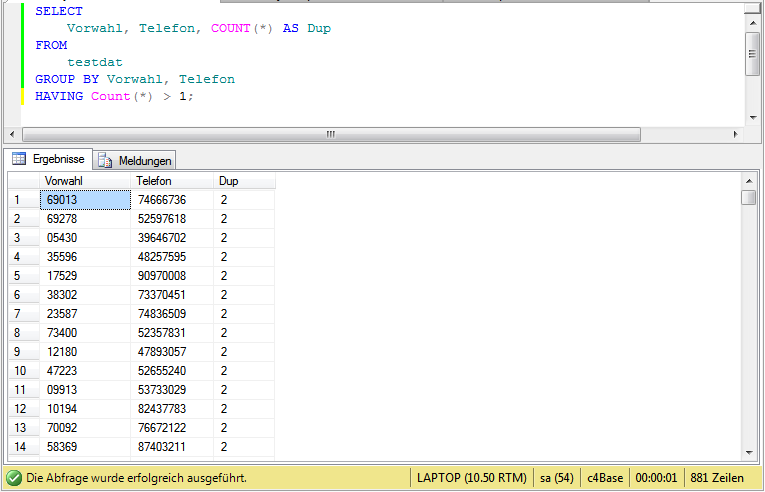
Viel anzufangen ist mit diesem Ergebnis nicht. Wir wissen jetzt zwar, daß wir doppelte Einträge in der Tabelle haben, aber das wußten wir vorher ja auch schon. Ein weiterer Nachteil dieser Abfrage ist die schlechte Performance im Vergleich zur nachfolgend vorgestellten Lösung.
Die wesentlich elegantere Variante ist die Verwendung einer sogenannten Correlated Subquery. Hinter dieser Art der Abfrage verbirgt sich ein indirekter Self-Join, da ein und dieselbe Tabelle in zwei miteinander in Wechselwirkung stehenden Abfragen gemeinsam verwendet wird. Über eine Correlated Subquery kann ich nun also alle doppelten (oder auch mehrfach vorkommenden) Datensätze mit jeweils einer einzigen SQL-Anweisung anzeigen bzw. löschen.
Mit der folgenden Abfrage lasse ich mir alle Datensätze anzeigen, in denen Vorwahl und Telefonnummer doppelt vorkommen.
SELECT Id, Vorname, Nachname, Strasse, PLZ, Ort, Vorwahl, Telefon
FROM testdat WHERE EXISTS (
SELECT Id FROM testdat Dup WHERE testdat.Vorwahl = Dup.Vorwahl AND testdat.Telefon = Dup.Telefon AND testdat.Id <> Dup.Id)
ORDER BY Nachname;Wie die nächste Abbildung zeigt, sind die gelieferten Informationen hier wesentlich ausführlicher.
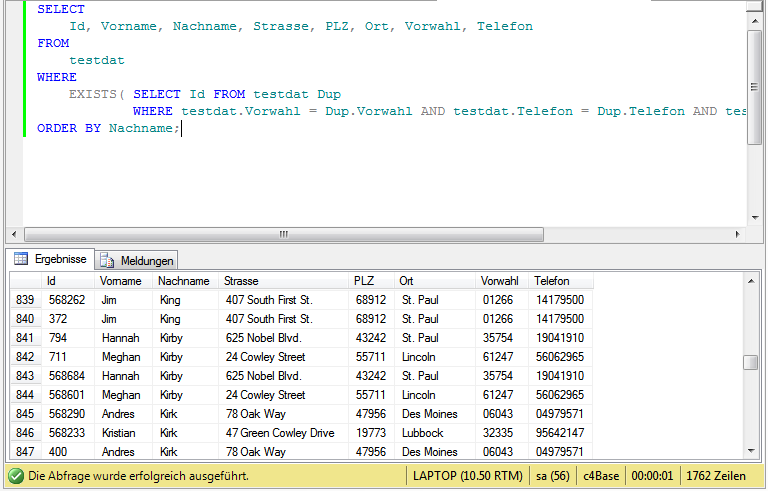
Auf gleiche Weise kann ich nun auch die vorhandenen Duplikate aus der Tabelle löschen:
DELETE FROM testdat WHERE EXISTS (
SELECT Id FROM testdat Dup WHERE testdat.Vorwahl = Dup.Vorwahl AND testdat.Telefon = Dup.Telefon AND testdat.Id < Dup.Id);Damit werden nun alle Duplikate mit der kleineren ID gelöscht.